[TOC]
图例 (Legends)
- 按照常见的 STAR 表述法说明相关工作:
- Situation 📄
- Task 🛠
- Action 💡
- Result 🏆
研究方向 (Research)
按照时间从近至远的顺序,对研究过的方向简要介绍。
该部分将主要介绍个人提出的研究内容和创新点。
- 博士课题方向
- 中文拼写纠正 (CSC: Chinese Spelling Correction)
- 研究如何提升模型对于真实场景录入错误的性能
- 基于真实录入错误的分布,生成更加符合真实场景错误的词粒度混淆集
- 参考多来源统计信息的差值作为错误可能性的依据
- 研究错别字模型对于错误 pair 的记忆能力
- 错误位置与纠错文本的任务拆解
- 探讨错字问题对于模型而言是拟合还是泛化
- 研究如何提升模型对于真实场景录入错误的性能
- 中文实体识别 (CNER: Chinese Named-Entity Recognition)
- 研究如何使得中文实体识别模型在边界检测上取得提升
- 将基于跨度的方法适用于中文命名实体识别,提出训练时的比例采样
- 显式建模模型预测时应该更倾向于实体的 surface string 还是 context
- 研究如何使得中文实体识别模型在边界检测上取得提升
- 嵌套因果提取 (NRE: Nested-causality Relation Extraction)
- 中文拼写纠正 (CSC: Chinese Spelling Correction)
- 非博士课题方向
- 自然语言接口 (NLIDB: Natural Language Interface to DataBase, or Text2SQL)
相关项目 (Projects)
按照时间从近至远的顺序,对作为主要贡献者(或主要贡献者之一)的项目进行简要介绍,
项目的详细信息以及其中的创新点将持续补充与更新。
- AutoDoc
- 📄 该项目为金融市场的信息披露文档进行智能复核
- 🛠 在智能复核项目中,负责长文档处理中的文本预处理及实体识别任务。
- 💡 负责为金融文档提取命名实体,主要关注语句中实体与上下文间的相互作用、实体边界的判断和增强实体识别的不变性,论文正投递至 IPMC (Regex + RuleTable & PyTorch)
- 🛠 在智能复核项目中,负责错别字纠正任务。
- 💡 设计与实现了金融文档相关的错别字检测与纠正模型 (Tensorflow & PyTorch),模型在金融及任务相关公开数据集上。
- 🏆 上述提及的各部分均已上线,作为金融文档复核的功能之一,为多家金融机构服务。
- 🏆 项目与港交所合作,获得中国首个 Regulation Asia 的年度 Outstanding Project 奖项。
- Glazer
- 负责金融文档相关的显式嵌套因果关系提取模型,相关论文已作为一作发表至 CCF-C类会议(Regular Paper & Oral Speech, PyTorch)
- 提供调研得到的市场需求,分享初步设计理念并参与制定产品功能,即募集说明书智能刷报系统,现已发布为“AI刷募集”软件,为中信证券在内的多家券商服务;后续参与实现新需求(指标变动原因检测)的开发,已完成并上线(Rules & PyTorch)
- Foundry
- Foundry:参与实现自然语言处理 AI Solutions 平台,贯通 NLP 任务的标注、训练、预测全流程,一体化处理文本语义(PyTorch)
- 三位主要实现负责人之一 (Yixuan Cao, Hongwei Li, Dian Chen)
- FinDoc-Bert
- 📄 负责于大规模中文金融语料上进行 Bert/Bert-wwm/Albert 模型的预训练任务,用于提供更加合适的预训练模型参数,
- 为多种平台与下游任务提供支持(Tensorflow & Pytorch)
- 该项目的两位主要实现负责人之一 (Feng Hong, Dian Chen)
- Mantra/Aireport/Text2SQL
- 首次作为主要负责人的大型完整项目,与海通证券直接对接。
- 实现NLIDB系统框架,即通过自然语言从数据库中获取繁杂类型信息的智能系统。
于深交所技术大会获得2019年度研究课题二等奖,第七届证券期货科学技术优秀奖(PyTorch)。 - 项目现于中金所课题中标,参与该项目的个性化部署。
- 进行语音文本转SQL实现智能数据检索引擎课题研究,一期验收完成。论文正投递至 CIKM。
- Quaff
- 基于明文文本存储的快速语料查询系统(Ripgrepy & Redis)
- 个人负责 python 端的 Ripgrepy,由同事帮忙部署于 Redis。
参与项目 (Involved)
按照时间从近至远的顺序,对参与项目进行简要介绍,
该部分为参与的项目中担任非主要职能或较少部分功能的。
- AutoDoc
- 参与公司创立之初的初期建设。
- 💬 作为公司的核心业务之一,于公司创立之初参与该项目的初期建设。 除上述提及的主要负责任务外,包括但不限于公开金融文档爬取、三元组提取、文档分类、文本跨页连接判断等。完善基本业务功能及框架(Rules & Theano)。
- 项目与港交所合作,获得中国首个 Regulation Asia 的年度 Outstanding Project 奖项。
- 负责金融文档相关的错别字检测与纠正模型,已上线作为金融文档复核的功能之一,为多家金融机构服务(Tensorflow & PyTorch)
- PDFlux
- PDFInsight:负责为该项目中金融文档相关的模型参数进行加密解密,该模块后续也沿用至公司其它包括 AutoDoc 在内的多个项目中(Tensorflow)
- PDFlux:参与实现表格语义合并模型,现线上模型已被新模型替代(TensorFlow)
- 开源社区项目 BBCM
- 作为目前中文错字最大社区 PyCorrector 的常用解决方案,广泛用于相关工作中。
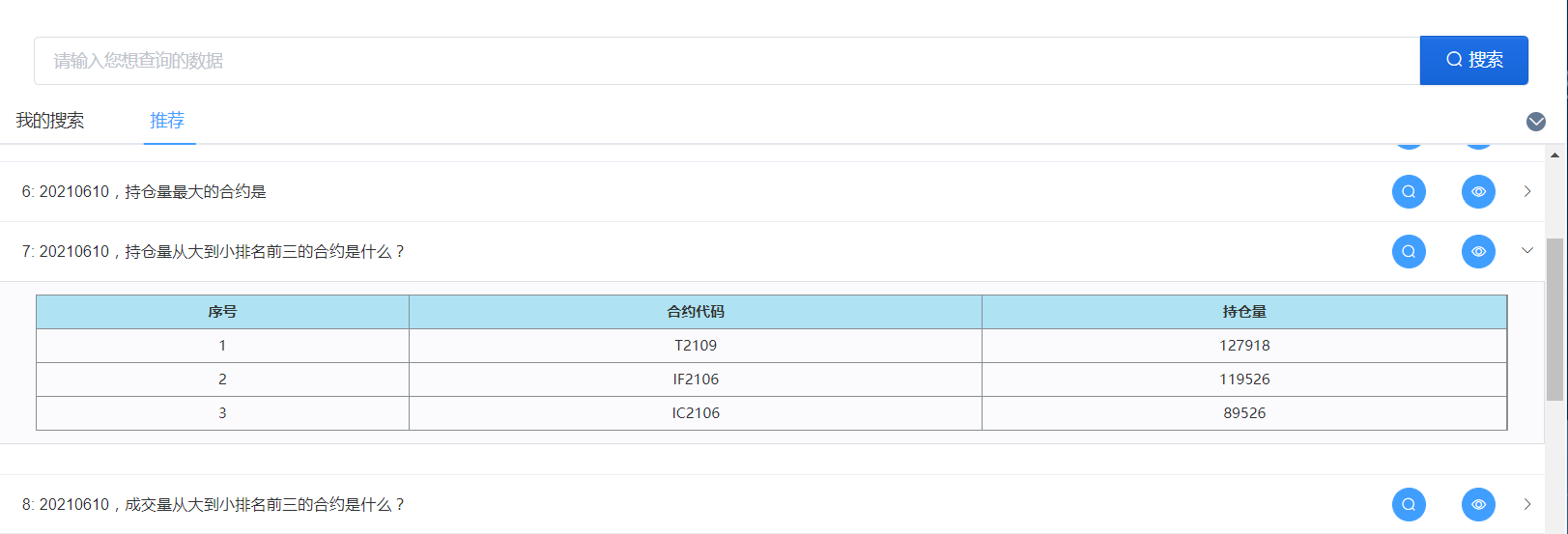
数据库的自然语言接口 (Natural Language Interface for DataBase)
YEAR 2020-2022
读博起即于导师的创业公司中,以实习生的身份参与各类项目(金融文档相关)
- 背景
- 在日常的生产中会产生大量的数据,如今各个公司都建立起自己的数据库,从而产生了需要从海量数据中挖掘与整理信息的需求,而操作数据库需要具有专业知识的人员。这些人员每日需要处理数量繁多但种类相近的需求,但由于表述不同、目标数据不同而不得已需要手动撰写大量的 SQL 查询,难以应对日益增多的查询和即时性的需求。
- 该任务学界称之为 NLIDB(Natural Language Interface for DataBase),工业界称之为 Text2SQL,接受用户输入的自然语言问询,系统生成可执行的SQL语句,在链接的数据库上执行后,返回结果整理成图表的形式提供给用户。
- 任务拆解
- 意图检测(Intent Detection)
- 关键信息填充 (Slot Filling) & 缺失信息补全
- 后处理,包括语法格式修复等
- 采取方案
- 在”可执行SQL”与”自然语言”之间加入”中间语言”(IR, Intermediate Representation)作为链接桥梁
- 实现知识库 (KnowledgeBase):”值-列-表”反查、数据库 Schema 热启动、实体链接
- 成果
{kind=link}
{kind=link}
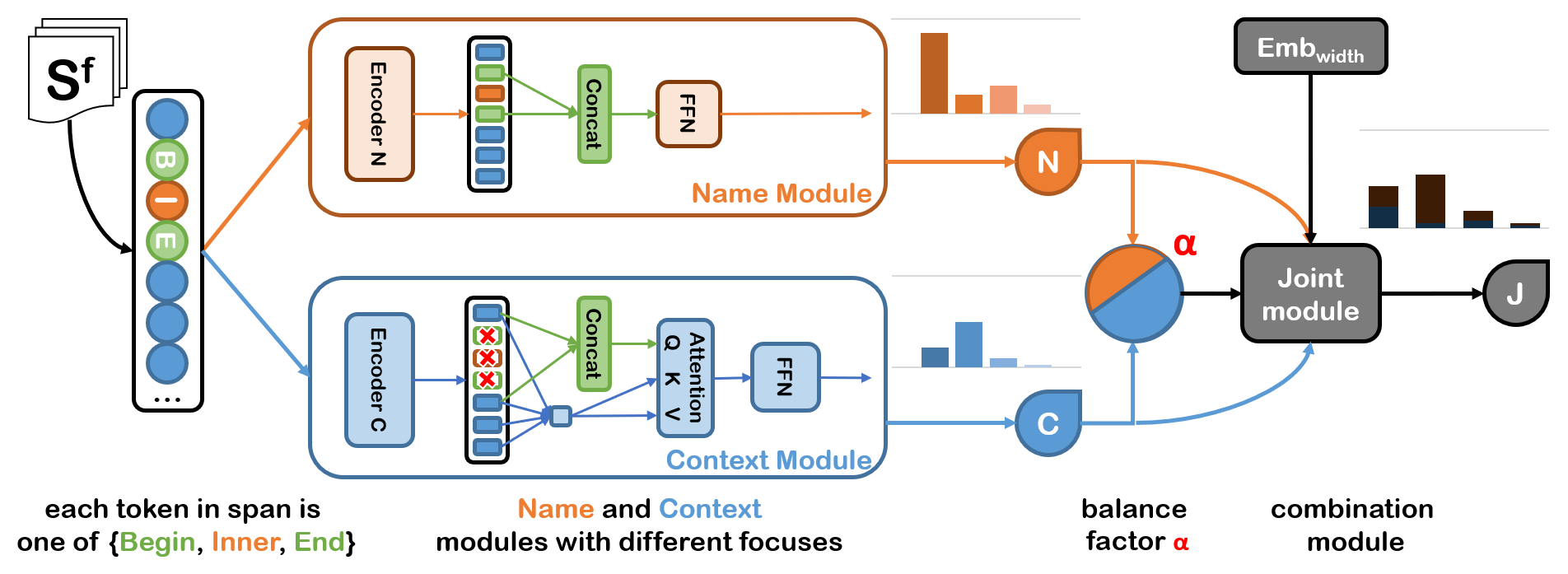
命名实体识别 (Named-Entity Recognition)
YEAR 2019-2022
于读博期间,作为毕设方向,研究中文文本中的命名实体识别。
作为 NLP 下游任务的基石运用于轻量化信息抽取 P5 项目中
- 背景
- 从纯文本句子中获取符合预定义实体类型的所有命名实体(在句子中的位置与实体类型)
- 任务拆解
- Span candidate detection
- Entity typing (classification)
- 采取方案
- Share: Span-based method
- Span candidate filtering strategies
- Explict modeling the context information
- 成果
- 研究成果形成论文《Explict Modeling the Context for Chinese NER》,已投递 ACL-ARR 中。
- 研究成果形成期刊《Span-based Chinese Named-Entity Recognition with Span Filtering》,已投递 JCST。
- 基于本命名实体识别的公司主要产品 AutoDoc 与港交所合作,获得中国首个 Regulation Asia 年度 Outstanding Project 奖项
- 开源项目 PURE, 当前方法在不使用额外知识与特征的情况下,可以在公开数据集 MSRA,Onto4,Resume 的排行榜上分别得到第 2,3,4 名的效果。
{kind=link}
嵌套关系提取 (Nested Relation Extraction)
YEAR 2019-2020
于读博期间,作为毕设方向,研究中文文本中的复杂关联提取,具有代表性的为嵌套关系提取。
- 背景
- 从纯文本句子中获取复杂的嵌套关联信息
- 任务拆解
- 嵌套模型定义 (自底向上 / 有向图 / 二分图)
- 图中间节点(关系节点)的表示
- 采取方案
- 自底向上的通用嵌套关联提取框架
IterativeNN - 面向因果嵌套关联特化的 Pairwise Causality Mining
- 自底向上的通用嵌套关联提取框架
- 成果
- 关于嵌套关联提取的研究成果
- 发表论文《Nested Relation Extraction with Iterative Neural Network》于 CIKM 及 FCS。Paper
- 跟随 Yixuan Cao 参与设计与实现自然语言处理 AI Solutions 平台
Foundry,贯通 NLP 任务的标注、训练、预测全流程,一体化处理文本语义。
- 关于显式嵌套因果关联提取的研究成果
- 发表论文《Pairwise Causality Structure: Towards Nested Causality Mining on Financial Statements》于 ICNLP/NLPCC。 Paper
- 根据本人调研得到的市场需求,分享初步设计理念并参与制定产品功能,即募集说明书智能刷报系统 Glazer。现已发布为”AI刷募集”相关软件与服务,为中信证券在内的多家券商服务。后续参与新需求(指标变动原因检测)的实现开发,已完成并上线。
- 关于嵌套关联提取的研究成果
金融文档文本预处理 (Fin-Document Text Preprocessing)
YEAR 2016-2018
读博起即于导师的创业公司中,以实习生的身份参与各类项目(金融文档相关)
相关工作包括但不限于:
- 撰写公开金融文档爬取的初版脚本,目标为公开财报及募集说明书
- 初版 PDF/Word 文档中的文本段落解析与汇总
- 设计简单的断句分类模型判断相邻句是否因文档跨页、跨栏而被分割的断句
- 负责初期的时间、金融属性、值的元组信息提取任务
- 负责文档中的数据清理,包括但不限于异常字、词、句的筛除
- 构造庞大的正则匹配知识库,以获取带单位名称的特殊值、特殊数字符号串等信息
YEAR 2019-2021
读博起即于导师的创业公司中,以实习生的身份参与各类深度模型相关基础建设
相关工作包括但不限于:
- 基于 BERT/BERT-wwm/Albert 为下游任务准备金融文本的预训练模型
- 负责公司项目中涉及的 Tensorflow 模型参数文件的加密解密
- 设计了初版的表格语义合并模型(沿用断句模型思路,现已被新模型替代)
- 基于 Ripgrepy 和 Redis 的明文文本存储的快速预料查询系统
Quaff
关联性与情感分析 (Relevance and Sentiment Analysis)
YEAR 2015-2017
于百度大数据实验室(BDL)实习期间,作为本科毕设课题,研究并实现基于在线研报的时事投资分析系统。
系统自动从在线研报网站轮询并实时解析。为从业者即时提供各篇新发研报涉及的股票及行业,并给出研报是看涨或看跌,其中部分模块及数据复用于百度后续项目。
成果形成毕设《Design of Real-time Investment Analysis System Based on Neural Network》,获重庆大学 2016 届校级优秀毕业设计(全计算机学院共3名)。
{kind=link}
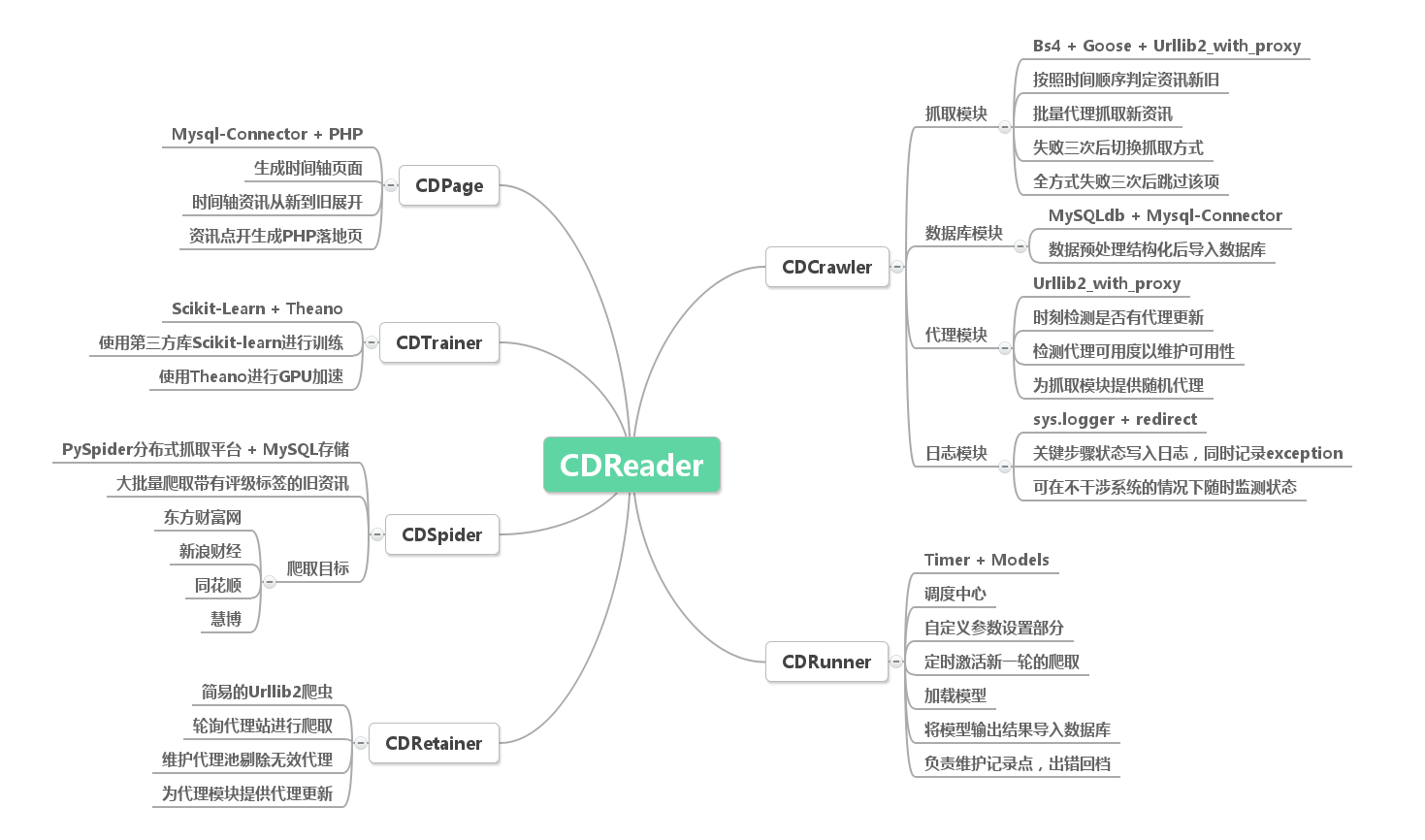
如思维导图所示,项目分为多个模块:
- 代理池模块,为爬虫模块维护可用代理池,已开源至 Github
- 自动轮询爬虫,基于常见爬虫库与
PySpider平台,自动轮询获取新增研报。 - 实时文本分析,与实验室的 Ganbin Zhou 学长合作,借助 KnowledgeCNN 的设计,计算文本关联性及情感极性分析。
- 展示部分使用简单的前端连接数据库,配置为时间线的形式。



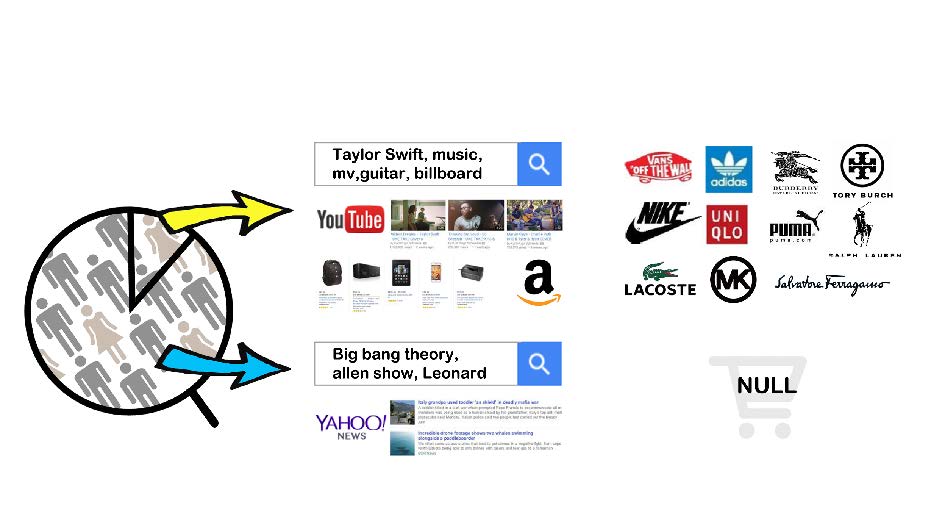
跨模态推荐 (Multi-modal Recommendation)
YEAR 2015-2016
于百度大数据实验室(BDL)实习期间,参与百度与大悦城合作的优惠券推荐项目。
协助导师 (Ping Luo) 及学长 (Su Yan) 完成研究中的数据分析、整理以及最终的成果展示工作。
成果形成论文《From Online Behaviors to Offline Retailing》发表于 KDD2016。原文链接